
Reflecting on OpenAI Dev day announcments

- Introduction
- Features & Changes in the Spotlight
- Performance and Feedback
- Unannounced Changes: Observations I've made
- Conclusion
Introduction
So, November 6th, 2023, marked the first-ever OpenAI Dev Day. I'll be honest—I had about as much interest in it as I do in watching paint dry. I expected another yawn-inducing spiel about GPT-4 fine-tuning. How mundane, right? Well, slap me with a keyboard and call me surprised, because I was dead wrong.
At the ungodly hour of 7 am, an email from OpenAI jolted me awake. Bleary-eyed, I noticed the title: “New platform updates from DevDay: GPT-4 Turbo, Assistants API, new modalities + GPTs in ChatGPT”. That got my attention faster than a caffeine shot. I dashed to my laptop and devoured the article, my excitement brewing like a storm. Before I knew it, an hour had passed, and I was deep into exploring the new features.
After some days of tinkering and prodding at the updates, I've stumbled upon something... intriguing. There's a philosophical angle I'm itching to write about, but patience—I need to verify my findings first.
The Mysterious Link
By the way, if you're itching to create your own GPTs, check out http://chatgpt.com/create. Why this link is hidden in the shadows is beyond me. It's not even in the change log (https://help.openai.com/en/articles/6825453-chatgpt-release-notes). Don't worry, I'll dive into these ninja-style updates soon enough.
Features & Changes in the Spotlight
GPTS: A Layman's Toy or a Glimpse of the Future?
So, "GPTS" – what a laughably unoriginal name. Sounds like something a bored intern came up with during a coffee break. Anyway, there's a whole blog post from OpenAI dedicated to this. You should probably read that for the mundane details. Here's my take: It gives your average Joe a shortcut to the "instruction" prompt, supposedly streamlining the initial interaction with GPT. But let's be real, it's barely distinguishable from just directly instructing GPT.
Now, the combo of vision and DALL·E access is intriguing, though it's not exactly a game-changer since ChatGPT-4 already has this trick up its sleeve. It feels like they're just giving you an option to uncheck a box you didn't know you had. The difference from the “assistant” feature is subtle, but I’ll get into that later.
The URL for this feature is bizarrely elusive, like it's playing hard-to-get. I stumbled upon it on Twitter, of all places.
My suspicion is that this GPTS thing is sneaking in the use of GPT-4 turbo models with a whopping 128k context. And why do I think that? Simple - they're practically begging you to upload your files as if they're some digital hoarders. You file would then be used as the GPTS initial context and be referenceable. With a beefy context like 128k, they're gearing up for something big. Think of it as trying to cram a novel's worth of information into a tiny digital brain.
Now, let's try and put those numbers into perspective: A typical novel has 80k-100k words, but that doesn't mean 80k tokens in the GPT world. Oh no, it's a bit more complicated than that. You see, every space, every punctuation mark gobbles up tokens like a greedy little gremlin. So when we're talking about a context size equivalent to a novel, we're actually dealing with a much larger number of tokens. The more sentences you have, the more it compounds. It's like trying to stuff an overstuffed suitcase – good luck with that.
The “Actions” feature is the real deal here, albeit not exactly newbie-friendly. It's like function calling, but without the fun of writing your own code. You're stuck with calling API endpoints, which sounds as exciting as watching grass grow. And the schema it uses? A total nightmare. Not something your average user, or even a seasoned developer, would want to wrestle with. I plan play around with this a lot more, but at first glance and I was already dreading it.
But hey, once you've set up your Frankenstein's monster of a GPTS, you can share it with the world, or just hoard it for yourself. They even have sharing settings like “Only me”, “Only people with a link”, and “Public”. How... quaint.
Oh, and a word of advice: if you're feeling brave enough to dip your toes into this technical swamp, check out OpenAI’s guide on prompt engineering at https://platform.openai.com/docs/guides/prompt-engineering. It's a lifesaver, trust me.
So, is GPTS a breakthrough or just a glorified toy? I'm optimistically leaning towards the former, but who knows? Maybe it'll surprise me.
Updated GPT-3.5 Turbo: A Lackluster Improvement?
So, they decided to give GPT-3.5 Turbo a little facelift, focusing on its ability to follow instructions. Honestly, GPT-3.5 has been about as reliable as a weather forecast – sometimes right, often not. I don't use this model much, just for trivial tasks where I don't mind if it acts up. Its main appeal? It's cheap. But hey, you get what you pay for, right?
After putting this "updated" version through its paces, I'm not impressed. The instruction-following still feels as clunky as a rusty robot. It's like trying to teach a cat to fetch – futile and a bit sad. This issue seems to be baked into GPT-3.5's DNA, a chronic case of misunderstanding what you actually want from it. There is a ninja update here, it is faster than the previous model – See the performance section below.
GPT-4 Turbo: A Step Up or Just a Side Step?
Okay, GPT-4 Turbo has been on my radar, and I've had my hands on it a bit to form an initial opinion. The 128k context window? Mind-blowing. It's like someone suddenly turned on the lights in a dark room – the possibilities seem endless. And let's be clear, this isn't some half-baked GPT-3.5 upgrade; it's a whole new beast. Plus, the price is right, which is always a bonus.
My bet is that this is the muscle behind GPTS, as I mentioned before. But when it comes to everyday use, it's a mixed bag. Sure, GPT-4 Turbo is faster and cheaper than GPT-4, but it's also a bit like a blunt tool compared to the sharper GPT-4. It's like choosing between a sledgehammer and a scalpel.
Here's the lowdown: GPT-4 Turbo is a massive leap from the somewhat dim-witted GPT-3.5, but it still lags behind GPT-4 in terms of smarts. Using it feels like driving a reliable but uninspiring and boring car – it gets the job done, but don't expect any thrills.
Now, about benchmarks. If we were to put GPT-4 Turbo on a performance scale, it might score impressively in controlled tests. But let's talk real-world usage – that's where the nuances come into play. It's like comparing a race car's speed on a track versus in city traffic. In a lab setting, GPT-4 Turbo might shine like a star, but throw it into the messy, unpredictable world of everyday tasks, and it starts to lose some of its luster. Good for certain tasks, but missing that X factor that makes GPT-4 stand out.
When reflecting on the capabilities and quirks of these AI models, it's clear that their development and performance are not straightforward. Just like life, the evolution of AI is far from a linear journey. "Life is not a straight line," and neither is the path of AI innovation. We see it in the unexpected leaps, the occasional stumbles, and the surprising turns that these technologies take. This unpredictability. This GPT4-Turbo feels like a branch in the narrative – a sibling.
So, what's my verdict? GPT-4 Turbo is more censored, less creative, and generally less intelligent than GPT-4. It's like the dependable workhorse in your digital stable – great for getting things done, but it lacks the charm and finesse of GPT-4. But it also hammers home the idea that what we have now and what we had in the past will be the most unrestrictive OpenAI models, every time they release a new update it feels worse and worse.
Assistants:
Here we go with the bad naming again.
Moving on to 'Assistants' – think of it as the developer's version of GPTS. These might end up in the GPTS stores, and if not, transitioning them to GPTS shouldn't be a Herculean task. But, and this is a big 'but', there are differences worth noting.
Assistants are designed for programmatic interaction. Sure, you can fiddle with the basic settings in the playground under the new “Assistants” tab, but the real deal happens when you start creating your own threads and logic for function calls. Using a file as input seems similar to GPTS, minus the part where it automatically calls DALL·E unless you’ve set up a function for it. It's like having a robot that won't make coffee unless you program it to.
There's this “Code Interpreter” function that's caught my eye. I haven't played around with it much yet, but from what I've seen in the docs (https://platform.openai.com/docs/assistants/tools/supported-files), it seems like it can spit out various file types and languages. At first glance, it looks like a way to run and execute Python in a GPT sandbox, but the documentation sends mixed signals. Does it only output to the desired language? Confusing to say the least.
For my initial foray, I uploaded a file and fed it instructions. Impressively, it stuck to my commands pretty closely, unlike the sometimes scatterbrained GPT-3.5 Turbo. It even had the courtesy to show me when and where it was referencing my input data. A neat trick, if I say so myself.

So, what's the verdict? It's too early for a full judgment. I need to dive deeper into both this and GPTS to give you a more detailed breakdown. Stay tuned for a more thorough post once I've had my fill of tinkering and testing.
Consistency Decode: A Thrilling Prospect or a Hardware Nightmare?
Now, let's talk about 'Consistency Decode'. This one really gets my gears turning.
If it turns out to be as groundbreaking as it sounds, it might just deserve its own spotlight in a separate article.
But here's the catch – the thing has a model size of a whopping 2.49GB for a VAE. That's like asking a house cat to pull a sled. My current setup might as well belong in a museum, so expecting it to handle this behemoth is probably wishful thinking. I'm gearing up to give it a shot, but let's be real, it's likely heading towards a spectacular failure.
Performance and Feedback:
Testing these models in Tokyo probably means hitting the closest server cluster, if not one right in the city. However I must say I don't have a clue where the data cluster is but based on my observations I am sure there is one nearby. The tests were run with a script I use for checking accuracy and quality – nothing too scientific, just a consistent set of tasks for each model. One of the topics? Cyberpunk Edgerunners – a great way to trip them up.
GPT-4 Turbo:
GPT-4 Turbo clocked in at 2:41.822 (m:ss.mmm) on the first run, costing around $0.13 OR $0.27 (My bad!). I ran this a few times to check costs and accuracy etc. It's noticeably faster than GPT4 and more logical than GPT-3.5, especially with accessing its previous context. However, a second run showed a huge time discrepancy, finishing at 1:43.579. A bit puzzling, that.
GPT-3.5 Turbo (gpt-3.5-turbo-0613):
GPT-3.5 Turbo, on the other hand, is frankly disappointing. Part of my tests returned the useless response “I'm sorry, but I don't have that information in my memory.” It completed the test in 1:27.784, but the quality was poor, costing less than $0.01.
New GPT-3.5 Turbo (gpt-3.5-turbo-1106):
This newer version of GPT-3.5 wasn't much better. It got confused and altered data when loaded into context. For instance, it made up tattoo locations for Rebecca from Cyberpunk Edgerunners – "Yes, she has a tattoo that reads 'PK DICK' on her neck, stomach, and right thigh. It's a reference to science fiction writer Phillip K. Dick.". It completed the test in 58.987 seconds on the first run and 1:02.537 (m:ss.mmm) on the second, but the instruction prompt still felt off. Notice how it out performance the older GPT3.5 Turbo model, why is that and why is the gap so wide?
I ran GPT3-5 and GPT4-Turbo multiple times and my GPT3-5 total was $0.07.
GPT-4 (8k Context Model):
GPT-4 was the slowest, taking 3:16.591 (m:ss.mmm). It did, however, correctly answer the tattoo question, adding a lot more detail to it. “Yes, she does. Rebecca has pink tattoos on her neck, stomach, and right thigh. In particular, her thigh tattoo reads 'PK DICK', a reference to the science fiction writer Phillip K. Dick. <snip>”
It also added some comments about clothing choices, which might not have been part of my dataset. (Post publish note: I check my dataset I had something in there which caused this, but that means GPT-4 had a wider and deeper understanding of my dataset.) The cost was around $0.41 for one run, but somehow totaled $0.61. It seems the price can escalate quickly with this one.
GPT-4's basic maths abilities were solid, accurately calculating Lucy's birth year from Cyberpunk Edgerunners ("If Lucy was 20 in 2076, that means she was born in 2056."), but that's not really a surprise for anyone familiar with GPT-4.

Unannounced Changes: Observations I've made
First off, the link for creating GPTS was like finding a secret door in a video game – I stumbled upon it on Twitter. Talk about low-key marketing. It's like OpenAI is playing a game of hide and seek with its features.
New GPT3.5 Turbo is faster.
ChatGPT Side:
Well if it's not obvious, the UI has been updated.
Now, ChatGPT has upgraded to the 32k context model for GPT-4, which is a noticeable shift from the 8k model. But something feels off. The quality seems diluted, like a watered-down version of its former self. Slightly biased, maybe a bit underwhelming. And hey, the 50 messages per 3-hour limit has vanished.
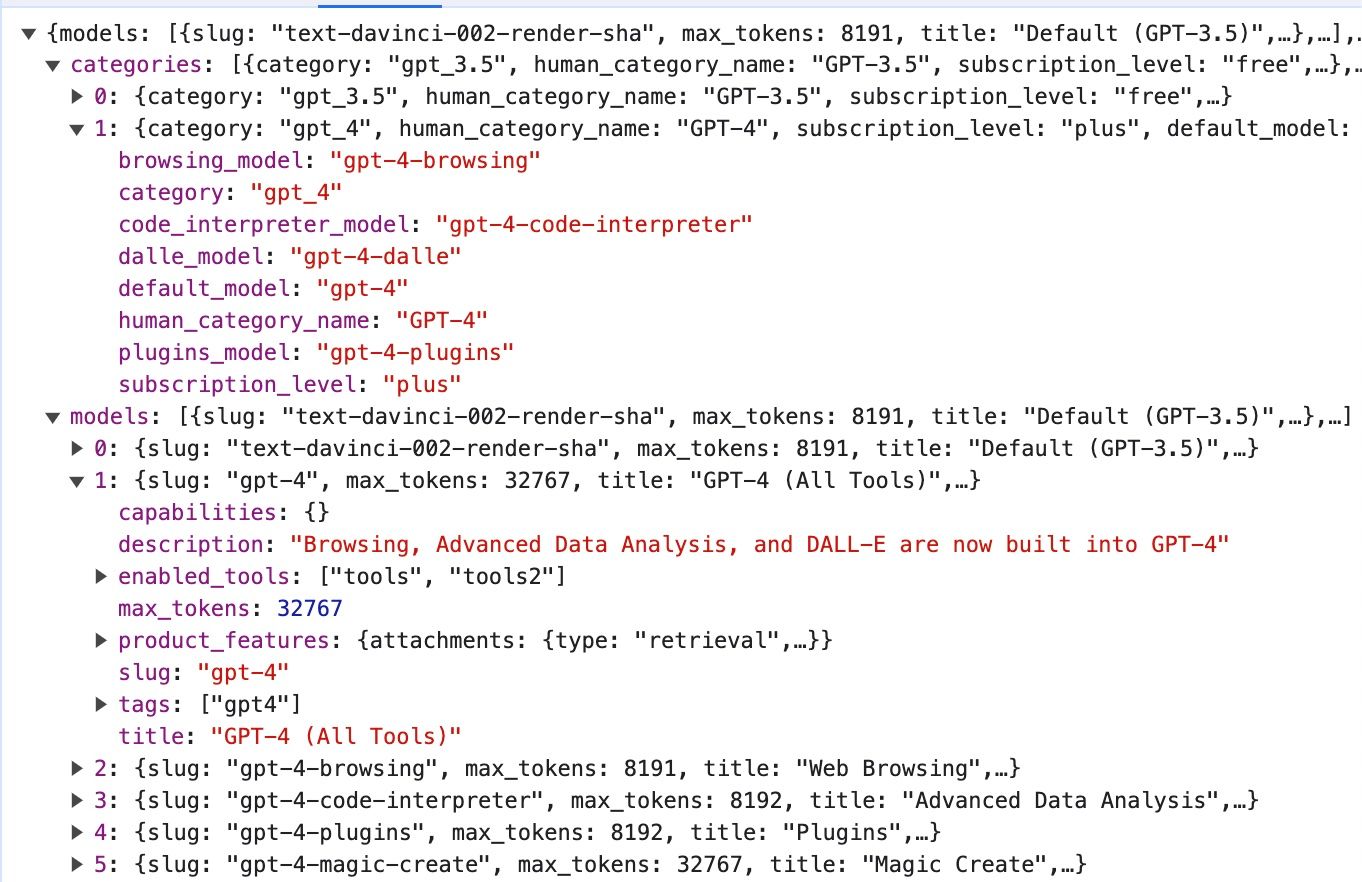
If you look at the developer tools on ChatGPT you would see something like
Developer/Playground Side:
Refreshed API usuage screen: They've now added a feature where you can break down your old bills. It's like finally being able to see what you're actually paying for – a novel concept, right?
“Files” Section in the Playground: This is pretty handy – it shows all the files used for fine-tuning and any uploaded for assistants. It's like having a neat digital filing cabinet, which is a welcome change from the usual chaos.
Fine Tuning Section in the Playground.
Conclusion:
Despite all the flashy updates and tools, there's this overbearing sense of being stuck in what I'd call a 'gilded cage.' It's like OpenAI has me chained to their innovation treadmill. Sure, they churn out impressive stuff – GPTS, expanded context windows, you name it. But let's not kid ourselves; it feels more like a velvet-lined trap than a tech paradise. I'm itching to break free, yet here I am, begrudgingly admiring their shiny but confining setup. It's like being served a gourmet meal when you're not really hungry – looks great, but leaves you feeling unsatisfied.