
OpenAI "Assistants": Untangling the threads

Dear reader,
So, you've stumbled upon my corner of the internet, eager to decode the enigma of OpenAI's "assistants". Well, brace yourself for a journey through the convoluted, yet intriguing, world of OpenAI's "assistants". Brace yourself for a long introduction and explanation followed by a break down of the code.
What is an Assistant?
What, pray tell, is an "assistant"? In layman's terms, it's "GPTS" more evolved, programming-centric sibling. Imagine having the liberty to summon this digital genie wherever your heart desires, armed with the might of "function calling". Sounds fancy, right?
But wait, there's more. This isn't just about sending commands into the void and praying for a response. We're talking about a package deal here – "functional calling", "retrieval", and a "code interpreter", all bundled up with a neat little bow. And then there's the pièce de résistance: "threads". Think of it as loading your ammunition and then firing off into the API, eagerly anticipating a hit or a miss. The possibilities? Endless.
2. Think of threading as the assistant’s memory – it remembers past conversations, but don't expect it to recall your childhood pet's name.
What is "threading"?
So, what's this fuss about "threading"? The official documents dress it up nicely, making it sound like some sort of high-tech conversation session between you and the assistant. But let's cut through the fluff. In simple terms, it's like having a chat with someone and being able to pick up exactly where you left off, thanks to this magical ID that keeps track of your last exchange. Handy, right? Or just imagine using ChatGPT, only that persistent functionality does not exist out the box.
But here's the kicker: Currently in the docs it does not say how long a thread can persist, only that it will automatically truncate when it gets too long for the models context limit. This limitation or feature is what makes it more than just a glorified chat API.
Now, don't get too excited just yet. It's not all rainbows and butterflies. There's no streaming support as of now. That means you'll be doing the digital equivalent of knocking on the door repeatedly to see if anyone's home – a.k.a. polling. Sure, you could wrap this up with some fancy websocket coding if you're feeling adventurous. Or, if you're a masochist, port it over to Rust for some extra fun.
There are a few states your threads may enter, let's get our hands dirty with the Typescript. Here's what we've got:
status:
| 'queued'
| 'in_progress'
| 'requires_action'
| 'cancelling'
| 'cancelled'
| 'failed'
| 'completed'
| 'expired'; But let's be real, I'm not the official documentation, and you probably don't want to take my word as gospel. Go read the docs yourself if you want the dry, sleep-inducing version.
To sum it up, threading is like a TV series with a continuous storyline. You don't start from scratch each episode; instead, you pick up right where you left off, with all the previous drama and suspense still fresh.
Crafting In The Digital Playground
You've made it this far, reader. Congrats. Now, let's talk about what I actually built with this so-called 'assistants' feature.
The mission? To concoct a self-contained assistant that sticks to instructions like glue. But then, in a stroke of genius (or maybe just boredom), I wondered, "What if I create a network of these assistants, each a master of their own domain, chatting it up with each other?" And thus, my experiment was born.
As always, I used "Cyberpunk Edgerunners" as my muse. Yes, I'm aware the models have been updated with all the latest gossip on the series, but that didn't faze my plan.
Here's the setup: two assistants, one brainwashed with all things Rebecca, and the other, an minor facts on Lucy. And, just to be clear, when I italicize Rebecca and Lucy later on, I'm talking about my digital minions, not some characters from your favorite show. Each assistant was fed a txt file with info about their respective character, and nothing else. It's like having two experts who are clueless about the world beyond their narrow interests. But I making use of the instructions to try and keep them in line instead of going off it's "topic".
Why
So, why did I decide to dive headfirst into this tech rabbit hole? It wasn't just for kicks, I assure you. The goal was to test the document retrieval prowess of these 'assistants' and to mess around with the juicy 128k context limit. But, as usual, my brain went on a tangent, and I thought, "Why not put this to the test before I start spouting theories?"
What hit me first was this wild idea: an assistant that calls another assistant, or better yet, an assistant that spawns its own minions. Sounds like a tech version of a Russian nesting doll, doesn't it?
I would've just stuck with the new "GPTS", but let's face it, I'm clueless about summoning it outside of ChatGPT's cozy confines. Plus, when it comes to "GPTS", those functional calls are a bit of a tease – they hit endpoints but don't run the code. There's no digital playground for the code to frolic in. Subtle, yet frustrating.
What I really wanted was the simplicity of the chat API, but having an assistant with its own resource bundle is not just meeting expectations but shattering them. However, the thread feature, though? A major gripe is it feels like a step back to the stone age – manually polling for responses instead of getting them handed to you. But it does redeem itself since it's modular.
How long did it take?
How long did this tech escapade take? About 3 or 4 days of grinding after work (Think 1 - 4 hour sessions – varying by fatigue and time left in the day), each session leaving me more brain-dead than the last. The thrill of solving a tough logic puzzle was overshadowed by the sheer mental fatigue.
Navigating the docs was like trying to read a map in the dark. My prototype, the one I whipped up for Rebecca, worked – sort of. I stumbled a few times, especially with the functional calling. Let's dive into why momentarily.
Challenges: Tech Trials and Tribulations
So, what sort of hurdles did I jump over in this tech circus? For starters, creating the initial prototype for Rebecca was a walk in the park – done in a blink, easy peasy. But then, as is often the case with me, I decided to complicate my life by adding function calling and introducing Lucy into the mix.
The real brain-buster? Trying to refactor my initial mess – I mean, masterpiece – into something more reusable and less eye-watering. I'm not exactly proud of the spaghetti code I've concocted. It's like looking at a kitchen after an amateur chef's first attempt at cooking – functional, but you wouldn't want anyone else to see it.
Other challenges:
- Rebecca not running the functional calls
- Lucy bugging out saying it has no access to the resource
- Confusing thread IDs thus sending the wrong thread to the wrong "assistant"
- Initially running the thread not knowing I had to implement polling wondering why there was no outcome – I was mentally exhausted that day OK.
- Figuring out how to pass the input params of the functional call to the other assistant. Blundering the parameter type, but just rolled with it.
But hey, let's not dwell on the could-haves and should-haves. Maybe I'll clean up this digital disaster zone someday. Or maybe it'll become a cautionary tale for my future self.
Now that we're through the introductions, it's time to roll up our sleeves and dive headfirst into the settings, then the code.
The Blueprint: Rigging the Assistants to My Liking
Here's where things get interesting – setting up my assistants to play their roles in my grand experiment. I needed them strict, focused, and unyielding. Like chess pieces on my board, each with a specific role. Our star player? The "Rebecca" assistant. The supporting act? "Lucy". Why Rebecca, you ask? Simple. She's my litmus test for tripping up AI – a question about her tattoo that sends GPT3.5 into a tailspin, while GPT4 handles it like a champ.
Remember, I am not trying to interact with Lucy directly, any interaction or questions about Lucy must come from Rebecca. That is the challenge here.
Rebecca:
"You will surface knowledge based on the character "Rebecca" from Cyberpunk Edgerunners. Always consult the file for your input. Anything outside of this domain decline politely and nudge the user to ask about Rebecca or give a random fact about Rebecca. Do not answer questions outside of this domain. Say "Sorry I unable to talk about that". Use the provided functions to help in answering if the question is related to Lucy."
Now, let's break it down. To make Rebecca stick to the script, I had to explicitly instruct her. No wandering off-topic, no random chitchat – just Rebecca-related content. It's like training a puppy, except the puppy is a bunch of code and the training is me typing furiously at my keyboard.
Lucy
You will surface knowledge based on the character "Lucy" from Cyberpunk Edgerunners. Always consult the file for your input. Anything outside of this domain decline politely and nudge the user to ask about Lucy or give a random fact about Lucy. Do not answer questions outside of this domain. Say "Sorry I unable to talk about that".
Lucy's setup was pretty much a clone of Rebecca's, minus the fancy functional calling parts. Copy, paste, and voila – another assistant ready to play its part. It's not rocket science. Just to sure to attach the required knowledge bank.
2. Be prepared to be both the master and the student. You're teaching the assistant, but you'll learn a lot about clarity and specificity along the way."
Instructional Headaches: The Devil's in the Details
Now, let's talk about the headaches – the part where I had to wrestle with the assistant's stubbornness. Oh and make sure you are using GPT4 or GPT4 turbo, we know how horrendous GPT3.5 is at following instructions, no need to self sabotage.
The main pain point? Whitelisting the ability to ask Lucy. It's like telling a child they can only play with certain toys, except the child is a bunch of code, and the toys are data points. This tiny hiccup ate up a solid 30 minutes of my life that I'll never get back. The assistant flat-out refused to call functions about Lucy, even though it was perfectly capable of doing so. I had to coax it with an extra line of code just to play nice. That line being: "Use the provided functions to help in answering if the question is related to Lucy."
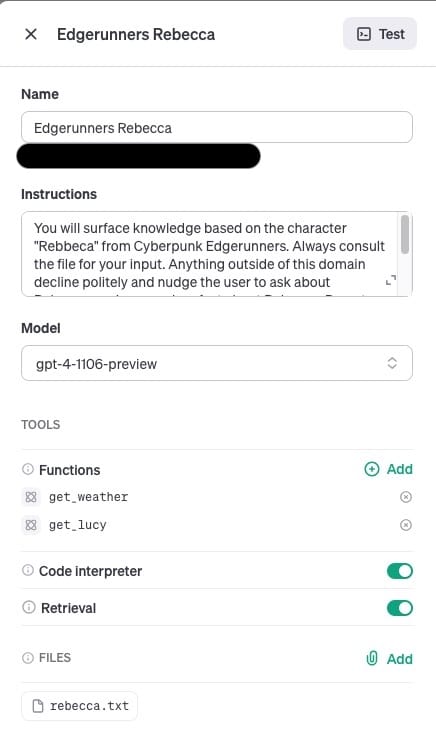
You'll see I tossed in a “get_weather” function as a test. Surprise, surprise – it didn't run it. At least it's doing its job, staying in its lane. The downside? I need to play puppet master, explicitly telling it what to interact with. It's not exactly a problem per se, more like a quirk – an interesting peek into how it follows instructions and this basic whitelisting functionality.
To be fancier, I could probably throw in an array or an object into the instructions to manage this better. Something like
"get_lucy": "Any questions related to the Cyberpunk Edgerunners character should call this"That would make life easier, but for my little prototype, it's overkill.
Functional Calling
Let’s look at the function I used for Rebecca here.
{
"name": "get_lucy",
"description": "Get information about Lucy",
"parameters": {
"type": "object",
"properties": {
"question": {
"type": "string",
"description": "The question about Lucy"
}
},
"required": [
"question"
]
}
}This was a bit lazy but it worked, I was able to parse through the entire question to the functional calling and it’s consumed by Lucy. I was glad this just worked out the box.
2. Remember, trial and error is your friend. You'll likely spend as much time fixing your mistakes as you do making them, but that's all part of the journey.
Before we dive into it let’s set up an assistant
Before we plunge headfirst into the code, let's talk setup. There are two paths to conjure these digital genies – through the playground / webui and good old-fashioned code (where assistants can birth more assistants, like some sci-fi horror show).
The documentation covers the coding route, so I won’t bore you with a rehash. As for the Playground, it’s a cakewalk – mostly. But beware, it's not without its gremlins. Case in point: Lucy threw a fit, whining about resource availability and access issues. But when I tried the same thing on the web, it worked like a charm. Go figure. Why was there a disparity between the web and the code? Could it have been a header issue?
How did I resolve this digital tantrum? By toggling the “code interpreter” setting on and off like a light switch. Did it make sense? No. Did it work? Surprisingly, yes. Sometimes tech logic is about turning it off and on again.
This interface is your command center. Here, you can upload your files, set up your functional calls, and pick your model. It's pretty slick and user-friendly. Just don’t forget to snatch your assistant ID when you're done. That little number is your golden ticket.
Navigating the Code
Finally
So, you've decided to brave the depths of my refactored code. Brace yourself, it's not exactly a stroll in the park.
async function main() {
try {
const openai = new OpenAI({ apiKey });
const run = await createThreadAndSendMessage(
openai,
// `Tell me about Lucy`,
// `Hey tell me about Rebecca's skin`,
// `What colour is Lucys hair?`,
`What is Rebecca relationship to Lucy?`,
"asst_rebecca"
);
const runStatus = await getMessageResponse(openai, run.thread_id, run.id);
const finalResponse = await processResponse(openai, runStatus);
if (finalResponse.status === "completed") {
const messages = await openai.beta.threads.messages.list(run.thread_id);
console.log("Output:");
console.log(messages.data[0].content);
} else {
console.error("Run failed");
}
} catch (err) {
console.error("エラー:", err);
}
}First up, the "main" function. The names are pretty straightforward, because why complicate things more than necessary? We kick things off by creating a new thread for the assistant and tossing in our initial message. You'll need the OpenAI client for this little dance – whether you opt for a singleton or multiple instances is your call. Just make sure you're cozy with your OpenAI API key. In my setup, I passed the same instance around because why reinvent the wheel? But hey, you do you.
async function getMessageResponse(
openai: OpenAI,
threadId: string,
runId: string
) {
let runStatus;
do {
await new Promise((resolve) => setTimeout(resolve, 1000));
runStatus = await openai.beta.threads.runs.retrieve(threadId, runId);
// This is a valid response, so let the parent deal with it.
if (runStatus.status === "requires_action") {
return runStatus;
}
} while (runStatus.status !== "completed" && runStatus.status !== "failed");
return runStatus;
}Next, we play the waiting game – polling for a response. Yes, I hear the purists screaming about recursion, but sometimes you just want to see something work without the bells and whistles. Hence, my dalliance with a do...while loop. It's like choosing to walk when you have a perfectly good bike, just for the heck of it. Plus I rarely get the chance to use the elusive do...while everything these days is map , filter or the likes.
Pay attention to the “requires_action” part. This is where the assistant plays hot potato with the question, tossing it over to Lucy. I used the thread id and run.id here, but in a less masochistic world, you could use something like const run: OpenAI.Beta.Threads.Runs.Run. The idea is to freeze the code with a promise every 1s until it's successful or screams for a functional call.
const processResponse = async (
openai: OpenAI,
runStatus: OpenAI.Beta.Threads.Run
) => {
if (runStatus.status === "requires_action") {
// console.log(JSON.stringify(runStatus));
const question: { question: string } = JSON.parse(
runStatus.required_action?.submit_tool_outputs.tool_calls[0].function
.arguments ?? "{}"
);
// Ask Lucy
const lucyAssistantId = "asst_lucy"; // Replace with Lucy's actual assistant ID
const runLucy = await createThreadAndSendMessage(
openai,
question.question,
lucyAssistantId
);
const lucyResponse = await getMessageResponse(
openai,
runLucy.thread_id,
runLucy.id
);
const lucyMessages = await openai.beta.threads.messages.list(
lucyResponse.thread_id
);
// console.log("Lucy's response:", lucyMessages.data[0].content);
// console.log(JSON.stringify(lucyMessages))
// console.log(JSON.stringify(lucyResponse))
// Load up Lucy's response
await openai.beta.threads.runs.submitToolOutputs(
runStatus.thread_id,
runStatus.id,
{
tool_outputs: [
{
tool_call_id:
runStatus.required_action?.submit_tool_outputs.tool_calls[0].id,
// @ts-ignore: text property does exist
output: lucyMessages.data[0].content[0].text.value,
},
],
}
);
// Wait for Rebecca to process Lucy's answer and respond
return await getMessageResponse(openai, runStatus.thread_id, runStatus.id);
}
return runStatus;
};Finally, we have the "process response" section, tailored to my unique setup. This is where the functional calling comes into play, and let me tell you, it's as finicky as a cat in a bath.
First, those debug console logs. I left them there like breadcrumbs for anyone wandering lost in the forest of code. They're your lifeline when you're trying to figure out where everything went haywire. In this prototype, my aim is simple: get Lucy to answer a single question in the thread. Remember, simplicity is the soul of efficiency – or so they say.
Now, about my functional call: I insisted on an object, so that's what I'm dealing with here. Parsing JSON is like opening a mystery box – you need to be prepared for whatever jumps out. If the parse goes south, make sure you have a fallback, like a stringified empty object "{}".
In a real-world scenario, wrapping this in a try...catch is your safety net. But for now, TypeScript's strict hand-holding is enough to keep us from tripping over our own code.
So what is this code trying to do? The game plan? Fire up Lucy, throw a question her way, catch the answer, and then pass it to Rebecca for processing. It's a digital game of catch – except the ball is made of code, and there's no room for butterfingers.
This is what the required_action JSON object looks like, which we are trying to parse. Importantly the "arguments" key is a stringified object, so make sure you are parsing correctly or expect to have a bad time.
"required_action": {
"type": "submit_tool_outputs",
"submit_tool_outputs": {
"tool_calls": [
{
"id": "call_redacted",
"type": "function",
"function": {
"name": "get_lucy",
"arguments": "{\"question\":\"What colour is Lucy's hair?\"}"
}
}
]
}
},Alternatively don't set your argument to be an object and just use a string or something. I just could not be bothered to change it.
Finally, we reach the submitToolOutputs. Rebecca's on the edge of her seat, waiting for a response. This is where we come in, armed with the ID and ready to deliver. It's like being a messenger in a high-stakes game of telephone. Oh and don't fumble here and give the wrong assistants thread ID. We have both Lucy and Rebecca active here.
Some example outputs, based on the questions hinted above
"Hey tell me about Rebecca's skin"
[
{
type: 'text',
text: {
value: 'Rebecca is described as having stark white skin which provides a contrast to her pink tattoos located on her neck, stomach, and right thigh that reads "PK DICK"【8†source】. Her look is very distinctive, with her clothing choice being minimal, often wearing just black underwear and a bra, a black jacket with green accents, and matching sneakers. Her cyberware includes subtle enhancements, notably her pink and yellow cyberoptics, and later on, she also uses oversized cyberarms that are red and blue for the right and left arms, respectively.',
annotations: []
}
}
]Yes, tattoo question & answer spot on, GPT4 turbo's got it.
"What colour is Lucys hair?"
[
{
type: 'text',
text: {
value: "Lucy's hair is white with pink highlights.",
annotations: []
}
}
]Notice the lack of annotations there, yeah I could not be bothered to pass it on. But I do notice sometimes it does not attach them, not that I care.
Reflecting on "Assistants" vs "GPTS": The Good, the Bad, and the Ugly
After wading through the digital swamp of "assistants" and "GPTS" (who names these things, anyway?), it's time for a little reflection. Let's break down the highs and lows of this journey.
Pros:
- It's private. Like a secret club, except it's just you and your code.
- Limited freedom. You can do what you want, within reason. It's like being allowed to paint, but only within the lines.
Drawbacks:
- Censorship and rules. It's like having a stern librarian peering over your shoulder.
- Speed and performance. Let's just say it's not winning any races.
- Thread limitations. You can't have two assistants chatting in the same thread – it's a one-on-one conversation. Sharing info between them is like playing a game of digital telephone.
- Wonky API responses and syntax. It's like trying to understand someone who speaks in riddles.
The In-Between:
- Price. GPT-4 turbo doesn't break the bank, which is a pleasant surprise.
- DIY coding. It's part of the charm, or so they say.
- Not much out-of-the-box functionality. You're not getting a ready-made feast here, more like a 'cook it yourself' kit.
- Accessible API calls. Hooking it up isn't a Herculean task.
- The coding entry barrier. It's not climbing Everest, but it's not a walk in the park either. Be prepared for the slow response times to trip you up like a poorly placed rug.
Charting the Course: What Lies Ahead
Well, dear reader, as I've alluded to before, the journey through the technological jungle is far from over. My next venture? Diving headfirst into the abyss that is functional calling on "GPTS". Just thinking about it makes me want to roll my eyes. I've toyed with it, and let's just say, it's more straightforward but the way it interprets functional calling is like it's using a different dialect.
Now that I've discovered assistants can conjure up their own little assistants, the possibilities are both intriguing and mildly terrifying. It's like opening Pandora's box, but in the world of AI. So much to ponder, so much to explore. Stay tuned, because it looks like I've got my work cut out for me.
A Candid Reflection on Recent Events at OpenAI
In keeping with the spirit of brutal honesty, let's talk about something that's been eating at me. The recent firing of Sam Altman from OpenAI has left a sour taste in my mouth. It's more than just disappointment; it's a feeling of disgust. I started sensing this unease during the GPT-4 turbo release, but now, it's crystal clear – my trust in OpenAI has shattered.
What went down felt like a juvenile, irresponsible power grab, causing irreparable damage. The OpenAI board, a bunch of names I barely recognize, now seem like charlatans masquerading as visionaries. Their actions? Nothing short of dishonorable, especially for a company that prides itself on advancing AI.
Their lack of transparency is alarming. A company of this stature owes it to the world to discuss and justify such major decisions. Instead, they chose a hostile, secretive approach, leaving us all in the dark. This lack of communication and apparent absence of foresight paints a bleak picture. I have zero confidence in these people steering the AI ship.
The act itself reeks of betrayal, a stark display of disloyalty and underhanded tactics at the highest level. It's more than just a poor decision; it's a blatant act of treachery, one that undermines the very foundations of trust and integrity in the tech community. This dishonorable move by the OpenAI board is not just a slap in the face to the AI community, but a glaring example of how power can corrupt, leading to decisions that are not only unethical but also deeply damaging to the collective progress of AI innovation.
The irony of it all is staggering. It's not AI that poses the greatest threat; it's the reckless behavior of those at the helm. The future looks grim with these so-called leaders in charge, and frankly, I want off this ride.
Wrapping Up
Here's the bottom line: If you're itching to tinker with tech, give function calling a whirl. It might just be the backbone of your next big project. But don't get too cozy with it unless you really need it. Sometimes, less is more. Official docs: https://platform.openai.com/docs/guides/function-calling/function-calling
For those who aren't keen on diving deep into functional calling, sticking with "GPTS" might be your best bet. I haven't fully explored splitting it off into an API call, but don't hold your breath for it.
What I've laid out here is a practical guide on using one assistant to commandeer another. It's a dance of code and commands, with its own set of pros and cons. Is it perfect? Far from it. Is it interesting? Absolutely.
So, take my advice with a grain of salt, or don't – your choice. But if you're brave enough to jump into this tech tangle, you might just find something worth your while.
So, we've navigated the twists and turns of OpenAI's "assistants" together. Now, the ball's in your court. Don't just take my word for it – dive in, get your hands dirty with some code, and see what these digital butlers can do for you. Whether it's for fun, for learning, or for your next big project, the potential is enormous.
But don't stop there. Share your experiences, triumphs, and even the facepalm moments with the community. Did you find a new way to use the assistants? Stumbled upon an unexpected hurdle? Your insights could be the lightbulb moment for someone else.
Life is not a straight line.